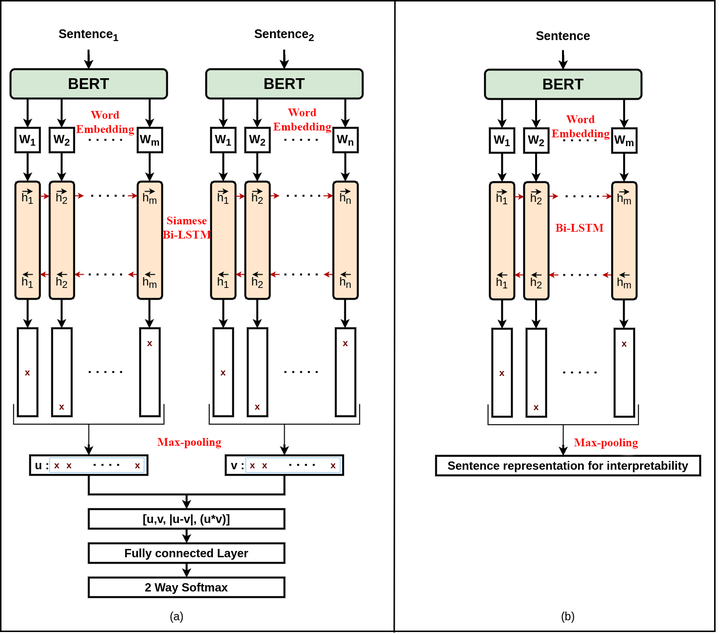
 The structure of the proposed framework.
The structure of the proposed framework.Abstract
Automatic personality detection has gained increasing interest recently. Several models have been introduced to perform this task. The weakness of these models is their inability to interpret their results. Even if the model shows excellent performance over test data, it can sometimes fail in real-life tasks since it may incorrectly interpret a statement. To investigate this issue, we evaluate two approaches. In the first approach, we generate sentence embeddings by training a siamese BiLSTM with max-pooling on the psychological statement pairs to compute the semantic similarities between them. In the second approach, we evaluate state-of-the-art pretrained language models to see whether their output representations can distinguish personality types. Both of these approaches outperform state-of-the-art models for this task with less computational overhead. We conclude by discussing the implications of this work for both computational modeling and psychological science.